Description
Proteins are organic molecules that are present in all living cells. As such, they are vital for survival. They come in various forms, such as enzymes, hormones, and cytokines that catalyze, regulate, and protect the body. Peptides are smaller proteins with molecular weights less than 10,000 g/mol. Proteins and peptides have a variety of functions in biological analyses. Specifically, peptides are critical in mass spectroscopy for the identification of proteins of interest based on molecular weight and sequence. Furthermore, peptides also facilitate analysis of protein structure and function, as synthetic peptides can be used to probe protein-peptide interactions.
Bio-Rad offers a wide range of highly active proteins and peptides for various applications such as ELISA, western blot and functional assays. Our portfolio includes cytokines, hormones, growth factors, and chemokines that demonstrate high purity and specificity. Our proteins and peptides are derived from a wide range of species such as humans, mice, bacteria, viruses, dogs, rabbits and rats. We also offer a variety of formats, such as linked, recombinant, or purified HRP. Our recombinant proteins have been primarily tested in relevant bioassays to ensure activity.
What is the difference between a peptide and a protein?
More proteins and peptides Recombinants are fundamental components of cells that carry out important biological functions. Proteins give cells their shape, for example, and respond to signals transmitted from the extracellular environment. Certain types of peptides play key roles in regulating the activities of other molecules. Structurally, proteins and peptides are very similar and are made up of chains of amino acids held together by peptide bonds (also called amide bonds). So what distinguishes a peptide from a protein?
The basic distinguishing factors are size and structure. Peptides are smaller than proteins. Peptides are traditionally defined as molecules consisting of between 2 and 50 amino acids, while proteins are made up of 50 or more amino acids. Furthermore, peptides tend to have a less defined structure than proteins, which can take on complex conformations known as secondary, tertiary, and quaternary structures. Functional distinctions can also be made between peptides and proteins.
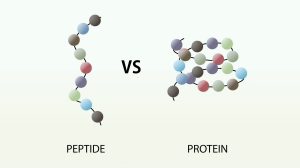
However, peptides can be subdivided into oligopeptides, which have few amino acids (eg, 2 to 20), and polypeptides, which have many amino acids. Proteins are formed from one or more polypeptides linked together. Therefore, proteins are essentially very large peptides. In fact, some researchers use the term peptide to refer specifically to oligopeptides, or relatively short chains of amino acids, and the term polypeptide is used to describe proteins or chains of 50 or more amino acids.
Protein quaternary structures
Many proteins are actually assemblies of several polypeptides, which in the context of the larger aggregate are known as protein subunits. Such multi-subunit proteins possess a quaternary structure in addition to the tertiary structure of the subunits. The subunits of a quaternary structure are held together by the same forces that are responsible for stabilizing the tertiary structure. These include hydrophobic attraction of nonpolar side chains at subunit contact regions, electrostatic interactions between oppositely charged ionic groups: hydrogen bonding between polar groups; and disulfide bonds.
Examples of proteins that have a quaternary (or quaternary) structure include haemoglobin, HIV-1 protease, and insulin hexamer. The haemoglobin molecule is a set of four protein subunits, two alpha units and two beta units. Each protein chain folds into a set of interconnected alpha-helix structural segments in a globin arrangement, so named because this arrangement is the same folding motif used in other heme/globin proteins such as myoglobin. This folding pattern contains a pocket that binds tightly to the heme group.
The four polypeptide chains are linked together by salt bridges, forming a tetrameric quaternary structure. In animals, haemoglobin carries oxygen from the lungs or gills to the rest of the body, where it releases the oxygen for cellular use. The oxygen-binding capacity of haemoglobin is decreased in the presence of carbon monoxide because both gases compete for the same binding sites on haemoglobin.
The binding affinity of haemoglobin for CO is 200 times greater than its affinity for oxygen. When haemoglobin combines with CO, it forms a very bright red compound called carboxyhemoglobin, which can make the skin of CO poisoning victims appear pink when they die. In heavy smokers, CO can block up to 20% of active oxygen sites. Similarly, haemoglobin has a competitive binding affinity for cyanide, sulfur monoxide, nitrogen dioxide, and sulfides, including hydrogen sulfide. All of these bind to heme iron without changing its oxidation state, causing severe toxicity.
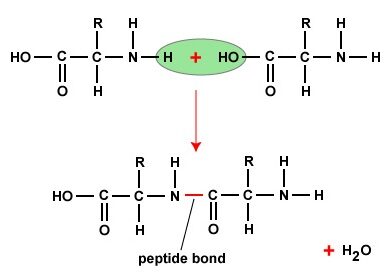
The peptide bond
If the amine and carboxylic acid functional groups on amino acids come together to form amide bonds, a chain of amino acid units, called a peptide, is formed. A simple tetrapeptide structure is shown in the diagram below. By convention, the amino acid component that retains a free amino group is drawn at the left end (the N-terminus) of the peptide chain, and the amino acid that retains a free carboxylic acid is drawn at the right end (the C-terminus). -terminal).
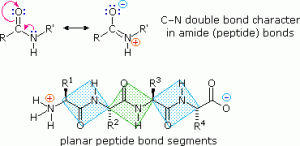
As expected, the free amine and carboxylic acid function in a peptide chain to form a zwitterionic structure at its isoelectric pH. The conformational flexibility of peptide chains is primarily limited to rotations about the bonds leading to the alpha carbon atoms. This restriction is due to the rigid nature of the amide (peptide) bond. This keeps the peptide bonds relatively flat and resistant to conformational change. The colour-shaded rectangles in the lower structure define these regions and identify the relatively easy rotations that can take place where the corners meet (ie, at carbon alpha). This aspect of peptide structure is an important factor influencing the conformations adopted by large proteins and peptides.
The Primary Structure of Peptides
Because the N-terminus of a peptide chain is different from the C-terminus, a small peptide composed of different amino acids can have several constitutional isomers. For example, a dipeptide made of two different amino acids can have two different structures. Therefore, aspartic acid (Asp) and phenylalanine (Phe) can be combined to produce Asp-Phe or Phe-Asp, remember that the amino acid on the left is the N-terminus. The methyl ester of the first dipeptide (structure on the right) is the artificial sweetener aspartame, which is almost 200 times sweeter than sucrose. None of the component amino acids is sweet (Phe is actually bitter) and derivatives of the other dipeptide (Phe-Asp) are not sweet.
A tripeptide made up of three different amino acids can be made into 6 different constitutions, and the tetrapeptide showed above (made up of four different amino acids) would have 24 constitutional isomers. When all twenty natural amino acids are possible components of a peptide, the possible combinations are enormous. Natural peptides of varying complexity are abundant. The simple and widely distributed tripeptide glutathione (first entry in the following table) is interesting because the carboxyl function of the N-terminal glutamic acid side chain is used for peptide bonding.
An N-terminal glutamic acid can also be closed to a lactam ring, as in the case of TRH (second entry). The abbreviation for this transformed unit is a plug (or pE), where p stands for “pyro” (those ring closures often occur on heating). The larger peptides in the table also demonstrate the importance of amino acid abbreviations, since a complete structural formula for a nonapeptide (or larger) would be complex and unwieldy. Formulas using single-letter abbreviations are coloured red.
The different amino acids that make up a peptide or protein, and the order in which they are linked by peptide bonds, is called the primary structure. From the examples shown above, it should be evident that it is not a trivial task to determine the primary structure of such compounds, even those of modest size. Complete hydrolysis of a protein or peptide, followed by amino acid analysis, establishes its crude composition but does not provide any binding sequence information.
Partial hydrolysis will produce a mixture of shorter peptides and some amino acids. If the primary structures of these fragments are known, it is sometimes possible to deduce part or all of the original structure by exploiting the overlapping pieces. For example, if a heptapeptide were composed of three glycines, two alanines, one leucine, and one valine, many possible primary structures could be written. On the other hand, if partial hydrolysis yielded two known tripeptide and two dipeptide fragments, as shown to the right, a simple analysis of overlapping units identifies the original primary structure.
Of course, this type of structure determination is highly inefficient and unreliable. First, we need to know the structures of all the overlapping fragments. Second, larger peptides would give rise to complex mixtures that would have to be separated and carefully examined to find suitable pieces for overlap. It should be noted, however, that modern mass spectrometry uses this superposition technique effectively. The difference is that bond breaking is not achieved by hydrolysis, and computers take on the tedious task of comparing a multitude of fragments.